
Grep置換に正規表現使ってる?書き換え作業は効率的に!


単純な作業は効率化したいよね
どうも。フロントエンドエンジニアの杉原睦弘です。
WEBサイト制作をしていると「特定のタグだけを書き換える」ということがままあります。
「でも文章が一律じゃないから置換できないし手作業で書き換えるしかないな」なんてことになっているあなた。
安心してください。置換できますよ。正規表現ならね。
文字列には色んなパターンがある
置換したい文字列には色々とパターンがありますよね。
例えば、「見出しの最後に~BTM~を追加する」という作業が発生した時には、言葉の上では「見出しの末尾に一文追加する」というだけのことです。
しかし、もしかしたら見出しのh1タグの中の構造はファイルによって違うかもしれません。
<h1>見出し</h1>
↑のように単純なものかもしれませんし、
<h1> 見出し </h1>
↑のようにインデントされているかもしれません。
<h1> <span>見出し</span> </h1>
もしかしたらspanタグだっているかもしれませんし、
<h1 class="title"> <span class="txt">見出し</span> </h1>
クラス名だってついているかもしれません。
こうなると単純な置換では対応しきれませんが、正規表現ならこういった場合にも対応ができます。
こんな感じにね!
検索文字列:(<h1(?:.|\n)+?)(<\/)
置換文字列:$1~BTM~$2
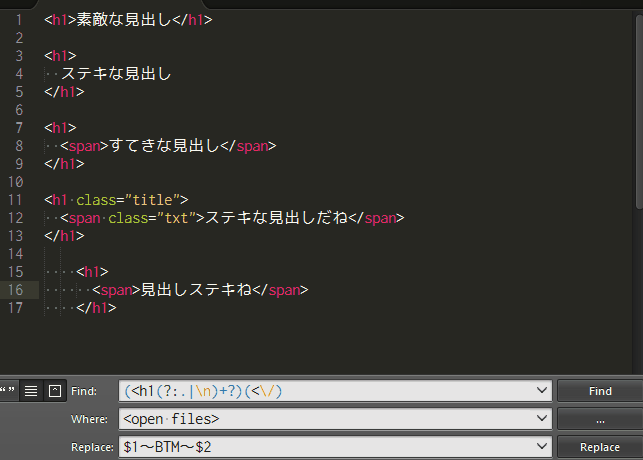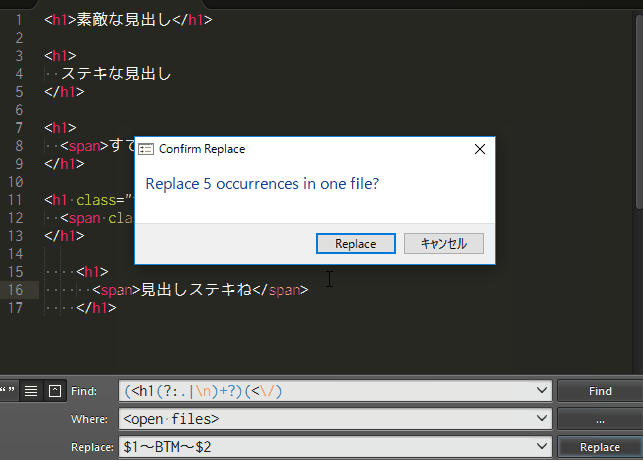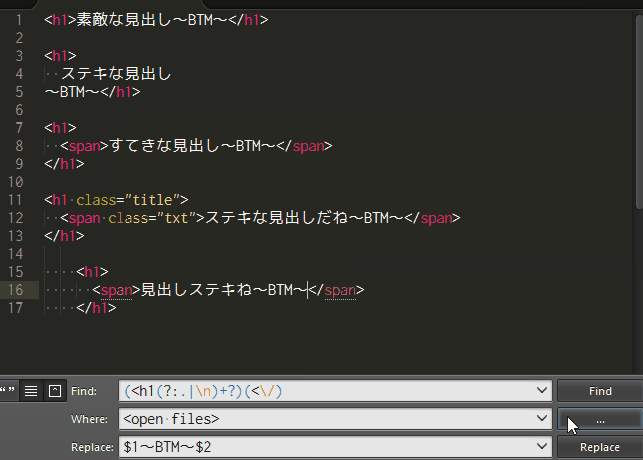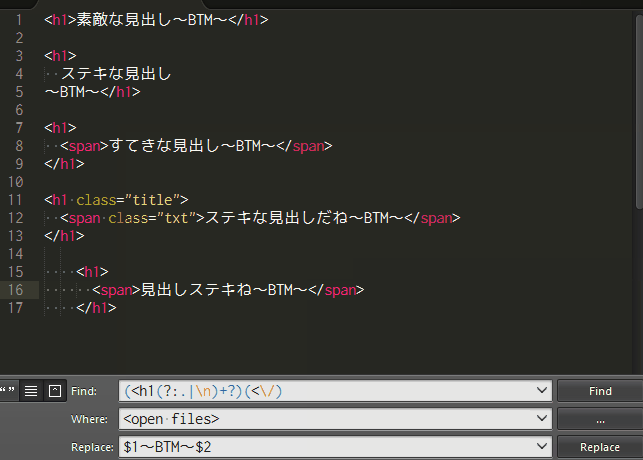
本記事では検索と置換に使った書き方(正規表現)で、どうして置換できるのか、順を追って説明していこうと思います。
正規表現とは
正規表現は、メタ文字(メタキャラクタ)と呼ばれる特殊文字を使って文字列のパターンを表現します。
例えば、郵便番号であれば、「数字が3つ」「-(ハイフン)」「数字が4つ」というパターンで成立しています。 正規表現の書き方をすると以下のようになります。
\d{3}-\d{4}
\dは半角数字を意味します。
{n}は繰り返しを意味します。
ですので、{3}は3回、{4}は4回繰り返すということを表現しています。
そのため\d{3}-\d{4}は
「半角数字が3回続いてて、その後にハイフンがあって、半角数字4回続いてる文字列だよ」という意味合いになります。
正規表現に対応したテキストエディタで\d{3}-\d{4}で検索した場合、
000-0000
123-4567
999-9999
といったどんな数字が入っていても検索にマッチします。
そして逆に、ハイフンがなかったり、繰り返しの数が違う文字列にはマッチしません。

※正規表現がマッチしている箇所が視覚的にわかりやすいように、http://rubular.com/という正規表現チェックを行えるサイトを利用してキャプチャを撮っています。
正規表現で検索する
「見出しの最後に~BTM~を追加する」という作業を行うために、まずは検索してみましょう。
前述した色々なパターンのh1のhtml構造には、必ずh1タグから始まる箇所が見受けられますね。
そして、
見出しの末尾に一文を追加するには、見出しの直後にある閉じタグを見つけられれば、置換ができそうです。
「<h1」から「</」までを検出したいと思います。
「.」ドットを使う
h1タグの中には、span等のタグや、半角スペースやタブ、改行などがあります。
「.(ドット)」は改行以外の文字にマッチしますので、ドットを使いましょう。
検索文字列:<h1.
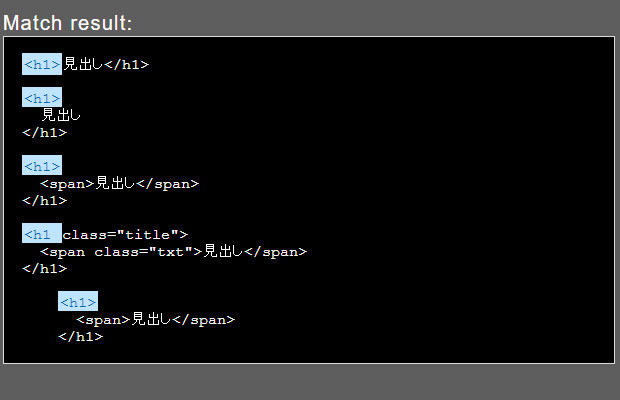
ドットのみだと繰り返す表現がないので、<h1>あたりしかマッチしませんね。
郵便番号の説明の時に繰り返し表現で{n}を使いましたが、今回は繰り返し回数が未確定ですので、他の繰り返し表現が必要です。
「+」プラスを使う
「+(プラス)」は直前の文字の1回以上の繰り返しを意味します。
検索文字列:<h1.+
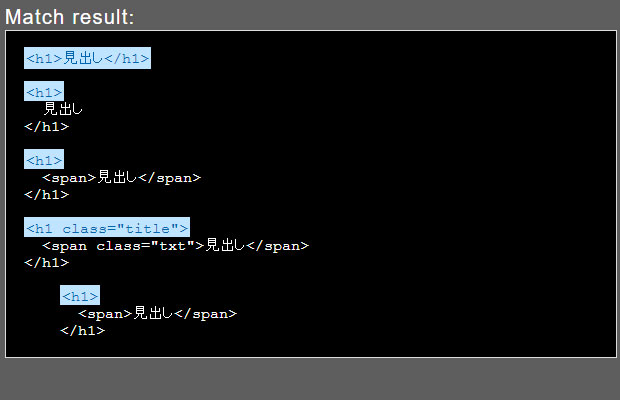
<h1がある行はマッチするようになりました。
しかし、ドットは改行を含まない表現なので、改行がでてくるとそこまでしかマッチしません。
「\n」改行を使う
改行を意味するメタ文字も併せて使いましょう。
改行を意味するメタ文字は「\n」です。
検索文字列:<h1.+\n
改行にマッチしているので見た目上は変化がありません。
改行の後に繰り返し表現を使っていないため、改行より後にマッチしてくれませんね。
しかし<h1.+\n+としても、プラスは直前の文字を繰り返すので改行が連続しているところにしかマッチしません。
<h1.+\n.+\nとすれば次の行も同じようにマッチしてくれそうですが、どうでしょうか。
検索文字列:<h1.+\n.+\n
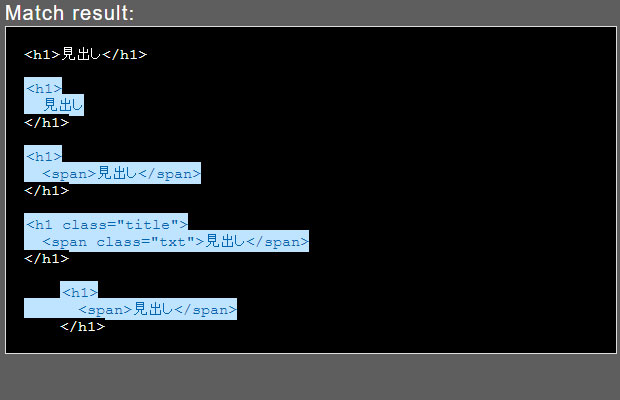
上手くいっているようにみえます。
しかしよくみると、一行だけで完結している<h1>見出し</h1>は改行がないので、マッチしなくなってしまいました。
「|」パイプラインを使う
改行・改行以外のどちらでもいい、ということを表現したいのでOR表現が必要となります。
ORを意味するメタ文字は「|(パイプライン)」です。
パイプラインを使って検索してみましょう。
検索文字列:<h1(.|\n)+
※ () ←の括弧は一塊のグループであることを表現します。
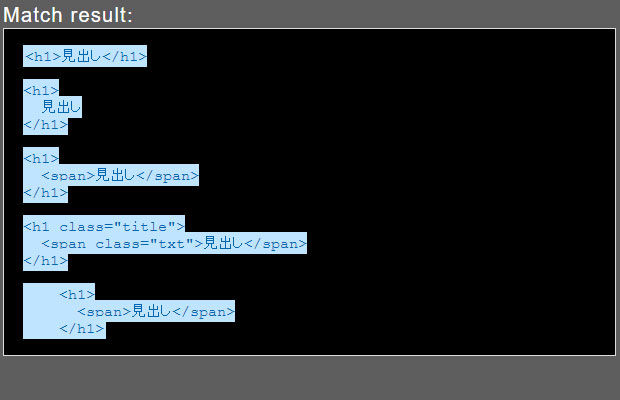
改行・改行以外の文字の繰り返しにはマッチするようになりましたが、「<h1」から文章全体の最終までマッチしてしまいました。
終わり位置を指定する必要がありますね。
今回の場合は「</」までが欲しいので、「</」が終わり位置となります。
検索文字列:<h1(.|\n)+<\/
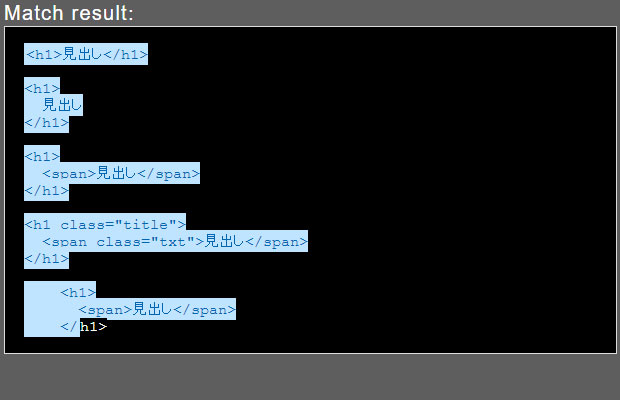
今度は文章の一番最後にある「</」までマッチしてしまいました。
最長一致と最短一致
プラスで繰り返しを表現するときに「?(クエスチョンマーク)」を一緒に書くと、マッチする範囲を変更することができます。
「+」と書いた場合は最長一致となり、一番遠い「</」までマッチします。
「+?」と書いた場合は最短一致となり、一番近い「</」がマッチします。
検索文字列:<h1(.|\n)+?<\/
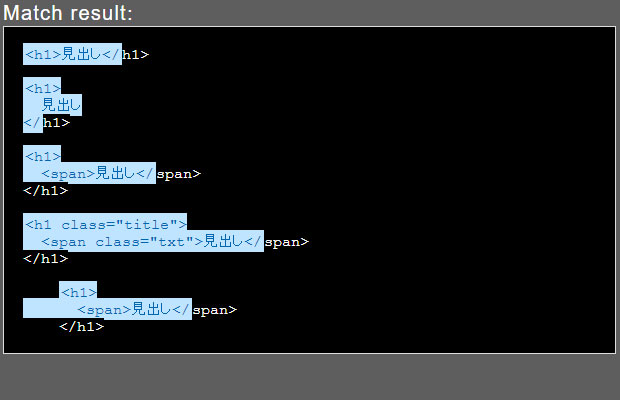
これで検出したい範囲が意図したとおりになりました。
正規表現で置換する
見出し部分の検出を正規表現を使って検索できたので「さーあとは置換するだけだぞ!」という段階です。
が、しかし。
正規表現を使って置換するときには
後方参照とは
正規表現には後方参照という機能があり、検索でマッチした文字列を、置換するときに参照して利用することができます。
「()」括弧はグループであることを表現すると前述しましたが、この「()」括弧の中が後方参照に使われるものとなります。
例えば、郵便番号で使った正規表現に、後方参照を使った書き方だと以下のようになります。
検索対象:
000-0000
123-4567
999-9999
検索文字列:(\d{3})-(\d{4})
置換文字列:3桁「$1」4桁「$2」
置換結果:
3桁「000」4桁「0000」
3桁「123」4桁「4567」
3桁「999」4桁「9999」
置換文字列の部分の $1 $2 と表記されている箇所が、後方参照の書き方です。
「()」括弧が登場した順序で $1 $2 という変数に値が代入されていきます。
今回の例でいえば、
(\d{3})が$1
(\d{4})が$2
に相対しています。
後方参照を使ってみる
それでは、後方参照の説明もしましたし、見出しの置換作業を進めたいと思います。
後方参照を使って置換するために、検索に使っていた正規表現を少し変更します。
<h1(.|\n)+?<\/
↓
(<h1(?:.|\n)+?)(<\/)
<h1 と <\/ をそれぞれ「()」括弧で囲っているのは、分かるかと思います。
(.|\n)の部分が(?:.|\n)に変わっているのは何故でしょうか。
部分的に後方参照させない
(.|\n)はグループを表現するために「()」括弧で囲いました。
しかし「()」括弧で囲ってしまったために、後方参照の変数に代入されてしまいます。
今回、(.|\n)の部分は後方参照に使いたくないところです。
そこで、括弧で囲ってグループ化するけど後方参照には使わないよ、ということを表すときには(?:)と記述します。
そのため、以下のように書き換えたのです。
(.|\n)
↓
(?:.|\n)
後方参照を使って置換する
そんなこんなで最終的な記述が以下のようになりました。
検索文字列:(<h1(?:.|\n)+?)(<\/)
置換文字列:$1~BTM~$2
まとめ
正規表現を知らなかった方には「便利な方法があるんだなぁ」ということだけ伝われば幸いです。
因みに、気づいている方も多い方思いますが・・・
<h1> ステキな見出し </h1>↓
<h1> ステキな見出し ~BTM~</h1>
って、
「~BTM~」の位置が改行の後に入って気持ち悪いことになっていますね。
私もちゃんと気付いてはいるんですよ!
ただちょっと力尽きたんです!
ではでは!
-
SNS
-
投稿日
-
カテゴリー
BTM Useful