
Hadoopって何?

皆さん、こんにちは。株式会社BTMの風間と申します。
先日、業務で初めて「Apache Hive」を扱う機会がありました。
Hiveを調べている時に「Hadoop」という単語が出てきたのですが、恥ずかしながら「Hadoopって何?」という状態でした。
そこで自分自身の備忘録も兼ねて、Hadoopの基本をまとめてみました。
1. Hadoopとは
「Apache Hadoop」は、膨大なデータを「汎用的なコンピュータの集合体」で
効率よく保存・処理するためのオープンソースの分散処理フレームワークです。主にJavaで開発されています。
「特殊な超高性能マシン1台で頑張るのではなく、どこでも調達できる汎用的なサーバーを並列に動かして、
超巨大なデータをさばこう」という仕組みになっています。
Hadoopは、Googleが公開した以下の2つの論文をベースに開発されました。
分散処理は難しく聞こえますが、「数千ページある分厚い本の中から『エンジニア』という単語が何個あるか数える」という作業を想像してみてください。
▶1人でやる場合: 1ページ目から順に、一人でコツコツ読み進めます。ページ数が膨大になると、終わるまでに何日もかかってしまいます
▶みんなでやる場合: 本を数百ページごとに小分けして、数十人の仲間に配ります。仲間が同時に自分の持ち分を数え、最後に結果を合算します
後者の方が、圧倒的に早く終わります。このように「巨大なデータを切り分けて、みんなで一斉に処理する」のが分散処理であり、Hadoopの基本的な考え方です。
2. Hadoopのエコシステムについて
Hadoopは、単一のソフトウェアではなく、多数のコンポーネント(HBase, Spark, ZooKeeperなど)からなる巨大な「エコシステム」です。
この記事では、その中でも最も基盤となる 「HDFS(保存)」 と 「MapReduce(計算)」 、
そして私が扱った 「Hive(SQLインターフェース)」 について簡単にまとめます。
3. HDFSについて
HDFS(Hadoop Distributed File System)は、巨大なファイルを複数のサーバーに分散して保存する「分散ストレージ」です。
例えば容量が数TBという巨大なファイルを扱う場合、HDFSはそれを128MBなどの「ブロック」単位に分割します。
そして分割したデータをDataNodeと呼ばれる複数のサーバーに保存します。
ファイルを分割しているのは、本を章ごとに小分けして配るのと同じで、後から皆で一斉に(並列に)読み取れるようにするためです。
また、各ブロックのコピーを作成し、別のDataNodeにも保存します。
これにより1台のサーバーが故障してもバックアップがあるため、全体として作業が止まらない「耐障害性」を確保しています。
ファイルは分割されますが、管理役のサーバー(NameNode)のおかげで、ユーザーはブロックを意識せず1ファイルとして見ることができ、
普通のファイル操作と同じ感覚でファイルを利用できます。
4. MapReduceについて
HDFSに保存された膨大なデータを「計算」する仕組みがMapReduceです。
ファイルからデータをMap(抽出)し、Reduce(集計)します。
開発者はこのMapとReduceの処理をJavaなどで実装します。実装にはHadoopが提供する「MapReduce API」を利用します。
このAPIに沿ってロジックを書くことで、分散処理に必要な以下のような複雑な制御は全てHadoopが自動で行ってくれます。
▶どのサーバーにプログラムを配るか
▶どのサーバーにどのデータブロックを読み込ませるか
▶途中でサーバーが壊れたら、どのサーバーでやり直すか
また、MapReduceは全てのデータを 「キー(Key)」と「バリュー(Value)」のペア で扱います。
「大量のログからエラー件数を数える」という処理を考えると次のような流れとなります。
1.Mapフェーズ:
開発者がAPIを使って「『Error』という文字を見つけたら、Keyを『Error』、Valueを『1』としたペア(Error: 1)を作れ」というプログラムを書きます。
これがデータを持つ各サーバーで並列実行されます
2.Shuffle(シャッフル)フェーズ:
ここはシステムが自動で行います。バラバラのサーバーで作られたペアの中から、同じKey(Error)を持つものを1箇所に集めます
3.Reduceフェーズ:
開発者がAPIを使って「集まったバリュー(1, 1, 1…)を全部足せ」というプログラムを書きます。最終的に「Error合計 500件」といった結果が出力されます
5. Hiveについて
「集計したいだけでJavaで実装するのは大変だな…」という課題を解決してくれるのが「Apache Hive」です。
HiveはSQL(HiveQL)を解釈し、裏側で自動的にMapReduceを生成・実行依頼してくれる翻訳機のような存在です。
例えば、HDFSに次のようなサーバーのログファイル(カンマ区切り)があるとします。
そして、ここからエラーログの件数を集計したいとします。

この場合、最初にファイルの構造をテーブルとして定義します。
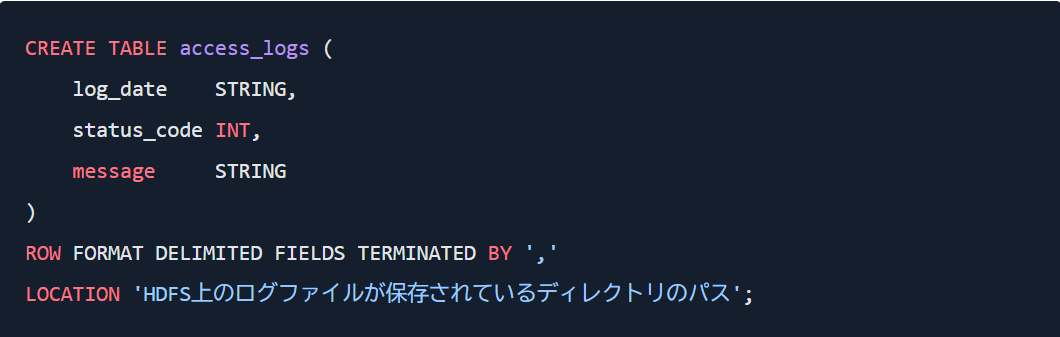
そしてSQLで集計します。

HiveはこのようにMapReduceの処理を実装しなくても、RDBMSを扱うような感覚で利用できます。
RDBMSは最初に型を定義し保存時に型のチェックをしますが、Hiveはファイルを保存してSELECTする瞬間に初めて定義を当てはめて解釈します。
MySQLなどのRDBMSと比較すると次のようになります。
| 比較項目 | RDBMS (MySQLなど) | Hadoop (+ Hive) |
|---|---|---|
| スキーマ適用 | Schema on Write (書き込み時) | Schema on Read (読み込み時) |
| 主な用途 | リアルタイムな検索・更新 | 巨大なデータのバッチ分析 |
| 拡張性 | スケールアップ(サーバー1台を強くする) | スケールアウト(サーバーの台数を増やす) |
| 更新処理 | UPDATE や DELETE が得意 |
基本は「追記」のみ |
| 応答速度 | ミリ秒〜秒(爆速) | 数秒〜数時間(じっくり) |
※上記のコードの実行は以下の環境にて行っています。
mac OS 15.7.1, Hadoop 3.4.2, Hive 3.1.3
まとめ
Hadoopの「汎用的なサーバーを束ねて力技で解決する」という仕組みは、
大量のデータを扱うにはとても合理的で、勉強になりました。
Hadoopが、ログ解析・機械学習・データ変換・データレイクなどで利用されている理由が分かりました。
まだ触り始めたばかりなので、使いこなせるように日々精進したいと思います。
ご興味がある方はぜひコチラをご覧ください!
-
SNS
-
投稿日
-
カテゴリー
Tech Blog