
ローカルLLMで社内AIコーディングエージェントを作ってみたら、結局Claude Teamが最強だった話

はじめに
こんにちは、株式会社BTM 古澤です。
AIコーディングエージェントを業務に導入したい。でも、こんな懸念がありました。
▶データがモデルの学習に使われるのでは? 業務コードを外部サービスに送るのは抵抗がある
▶コストが読めない。 API従量課金だと月末に請求を見て青ざめそう
▶社内で共有できる基盤が欲しかった。 個人のAPIキーに依存したくない
「ならローカルLLMで自前のAIエージェント基盤を作ればいいのでは?」
そう考えて、AWS EC2のGPUインスタンス上にOllamaを立て、認証付きプロキシサーバーを構築し、
Cline(VSCode拡張)から利用できるようにしました。
本記事では、その構築と検証の結果、そしてローカルLLM・Bedrock・Claude Teamのコスト比較を通じて
「社内でAIコーディングエージェントを導入するなら何が最適か」を考察します。
作ったもの:LLM Gateway
アーキテクチャ
Google OAuth認証付きのLLMプロキシサーバーです。OllamaをバックエンドとしてOSSモデルをホスティングし、
認証を経由してClineから利用できるようにしています。
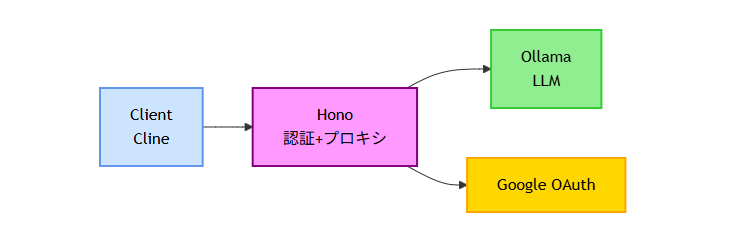
▶Hono(TypeScript)で認証・プロキシサーバーを実装
▶Google OAuthで社内ドメインのユーザーのみアクセス可能に
▶OllamaでOSSモデル(Qwen3-Coder)をホスティング
▶AWS EC2 g5.xlarge(NVIDIA A10G 24GB VRAM)上で稼働
▶ClineからはOllamaのAPIを直接利用(ClineはOllama APIにネイティブ対応している)
この構成なら、社内のデータは自社インフラ内で完結し、外部に送信されることはありません。
なぜこの構成にしたか
モデルの選定について、Qwen3-Coderはコーディング系ベンチマークで高い成績を記録しており、
OSSモデルの中でコーディングエージェント用途に適していると判断しました。
正直なところ「30Bクラスのモデルでも実用的に使えるのでは?」という期待もありました。
パラメータ数が小さければGPUコストも抑えられるので、もし使えるならコスパは最強です。
ClineはOllamaのAPIにネイティブ対応しているため、OpenAI互換APIを経由せずにOllamaのAPIを直接利用できます。
そのため、Ollamaの前段に認証付きプロキシを挟むだけで「認証付き社内LLMサーバー」が実現できました。
Google OAuthを使うことで、特定ドメインのメンバーだけがアクセスできる仕組みです。
インフラはCloudFormationで構築しました。これが後に効いてきます。
当初は東京リージョン(ap-northeast-1)で構築していたのですが、
GPUインスタンス(g5.xlarge)のキャパシティ不足でインスタンスが起動できない事態に遭遇しました。
そこでバージニア(us-east-1)にリージョンを変更したのですが、CloudFormationテンプレート化していたおかげで、
リージョンを切り替えてスタックを作り直すだけで移行が完了しました。
手作業で構築していたら、この移行はかなり面倒だったはずです。
ローカルLLM用途でEC2 GPUインスタンスを使う場合は、バージニア等の米国リージョンの方がキャパシティに余裕があり、
かつ料金も約30%安いのでおすすめです。
検証結果:使えるが、限界もある
検証環境
| 項目 | スペック |
|---|---|
| GPU | NVIDIA A10G(24GB VRAM)/ EC2 g5.xlarge |
| モデル | Qwen3-Coder |
| コンテキストウィンドウ | 32Kトークン |
| エージェント | Cline(VSCode拡張) |
参考までに、クラウドLLM(Claude Sonnet等)のコンテキストウィンドウは200Kトークンで、ローカルLLMの約6倍です。
ぶつかった壁
実際に使ってみると、いくつかの課題に直面しました。
1. 長時間使うと応答が返らなくなる
Clineでタスクを進めていると、ある時点から急に応答が止まります。
推定原因はコンテキストウィンドウの上限(32K)に達していること。
クラウドLLMの200Kと比べると、かなり早い段階で限界が来ます。
2. モデルロードに1分以上かかる
Ollamaはリクエストが来たタイミングでモデルをVRAMにロードしますが、
32Bモデル(約20GB)のロードには1分以上かかります。
「ならKEEP_ALIVEを長くすればいいのでは?」と思いましたが、
モデルを常駐させると長時間利用によるスタック問題が発生し、
結局サーバーの再起動が必要になるというジレンマがありました。
3. 複数ファイルにまたがる調査が苦手
「このバグの原因を調べて」のような、複数ファイルを横断して調査するタスクは精度が低かったです。
コンテキストウィンドウが狭いため、参照した情報を保持しきれないのが原因と考えられます。
現実的に使えたこと
一方で、比較的単純なタスクであれば効率化できることもわかりました。
| ユースケース | 所感 |
|---|---|
| ユニットテストの作成 | 1ファイルの機能を把握する程度なら対応可能 |
| PDF・Excelの調査 | 資料から情報を抽出するタスクは実行できた。要件定義時に活用できそう |
| DBスキーマのコード生成 | モデルファイルやマイグレーションファイルの生成に対応可能 |
共通しているのは「単一ファイル・単一資料を対象とした定型的なタスク」であるという点です。
バイブコーディング(自然言語で指示してAIにコード全体を書かせるスタイル)のような使い方ではなく、
サブエージェント的に限定されたタスクを任せる使い方が向いていました。
コスト比較:ローカルLLM vs Bedrock vs Claude Team
「性能に制約があるなら、コストメリットで勝負できるのでは?」
そう考えて、3つの構成でコストを比較しました。
前提条件
▶1日8時間、月20営業日(160時間/月)
▶5名チームでの利用を想定
▶為替レート: 1$ = 150円
1. LLM Gateway(EC2 + Ollama)
自社EC2インスタンス上でOSSモデルを稼働。インフラ固定費のみ。
| リージョン | 月額 | 1人あたり |
|---|---|---|
| 東京 | 約 $243 | 約 $49(約7,350円) |
| バージニア | 約 $170 | 約 $34(約5,100円) |
ユーザー数に依存しない固定費です。コストの約95%がEC2インスタンス代です。
2. Amazon Bedrock(Claude Haiku 4.5)
従量課金制。Claude Code + Bedrockの構成で実測しました。
なお、Bedrockではユーザーの入出力データがモデルのトレーニングに使用されることはなく、
AWSネットワーク内で通信が完結します(参考)。
実測値:6.5時間の開発利用で約$27(約$4.2/時間)
月額に換算すると 約$672/ユーザー(約10万円) になります。コストの約80%がプロンプトキャッシュ関連でした。
プロンプトキャッシュは、こうした繰り返し部分をキャッシュして再利用する仕組みです。
キャッシュ読み取りの単価は通常の入力トークンより大幅に安い(1/10程度)ものの、
エージェントの特性上キャッシュされるトークン量自体が膨大になるため、結果的にコスト全体の大部分を占めることになります。
3. Claude Team プラン
Anthropic公式のサブスクリプション。入出力データはデフォルトでモデルトレーニングに使用されません(参考)。
| 項目 | 内容 |
|---|---|
| 月額(年払い) | $20/ユーザー |
| 月額(月払い) | $25/ユーザー |
| 最低人数 | 5ユーザー |
| コンテキストウィンドウ | 200Kトークン |
| Claude Code | 利用可(Standardシートに含まれる) |
| データのトレーニング利用 | なし(デフォルト) |
※ Bedrockは実測値($4.2/時間)を月間業務時間(160時間)に換算した推定値。利用量に応じて変動します。
比較まとめ
| 観点 | LLM Gateway | Bedrock Haiku 4.5 | Claude Team |
|---|---|---|---|
| 料金体系 | インフラ固定費 | トークン従量課金 | ユーザー固定費 |
| コスト予測性 | 高い | 低い | 高い |
| コンテキストウィンドウ | 32K | 200K | 200K |
| モデル性能 | OSSモデル | Claude Haiku 4.5 | Claude Sonnet / Opus |
| Claude Code | 不可 | 可(API経由) | 利用可 |
| データプライバシー | 自社インフラ内完結 | トレーニング利用なし | トレーニング利用なし |
結論:Claude Teamが最も費用対効果が高い
月並みな結論ではありますが、数字で比較すると明確でした。
Claude Code(Teamプラン)が、費用・性能・運用負荷のすべての面で優れています。
▶月額3,000円/ユーザーで、Claude Code・200Kコンテキストウィンドウ・Sonnet/Opus等の高性能モデルが使える
▶Bedrockで同等の利用をすると月額約10万円/ユーザー。Teamプランの約34倍
▶LLM Gatewayは月額5,100円〜と安価だが、
コンテキストウィンドウの狭さ(32K)とモデル性能の限界から、
実用的なコーディングエージェントとしては力不足
▶BedrockもClaude Teamも、入出力データはデフォルトでモデルトレーニングに使用されない。
「データが学習に使われるのでは?」という当初の懸念は、ローカルLLMに限らずクラウドサービスでもクリアできる
ローカルLLMに価値がないわけではない
ただし、ローカルLLMが完全に無価値というわけではありません。
▶単一ファイルを対象としたユニットテスト生成や定型コード生成には十分使える
▶クラウドLLMのサブエージェントとして、特定のタスクを委譲する構成なら費用対効果は高い
▶データを一切外部に出せない要件がある場合は、依然として有力な選択肢
とはいえ、「社内でAIコーディングエージェントを導入したい」という目的に対しては、
自前でインフラを構築・運用するよりも、Claude Teamプランを契約する方が圧倒的にシンプルで、
コストも安く、性能も高いというのが今回の検証で得られた結論です。
おわりに
「ローカルLLMなら無料で使い放題では?」と思って始めたこの検証ですが、
GPU付きEC2の時間単価を計算すると全然無料ではなく、性能面でもクラウドLLMには遠く及びませんでした。
AIエージェントの世界は進化が速く、今後ローカルLLMの性能が向上すれば状況は変わるかもしれません。
しかし2026年現在の選択肢としては、Claude Teamのような定額サービスが最も現実的な解だと感じています。
この記事が、社内でのAIエージェント導入を検討している方の参考になれば幸いです。
ご興味がある方は是非こちらをご覧ください。
-
SNS
-
投稿日
-
カテゴリー
Tech Blog