
単純じゃないシステム障害-世界初のバグに学ぶ-

こんにちは、えんピぐらしです。
Linuxとネットワークを中心としたインフラ屋として、
今まで10年近く仕事をしてきました。
今後は自分が興味を持った技術的な話をどんどん書いていこうと思ってるので、
よろしくお願いします。
ANAの国内線旅客システムのシステム障害
さて、今回は「ANAの国内線旅客システムのシステム障害」について、書こうと思います。
記憶に新しい方も多いと思いますが、
3月22日にANAの国内線旅客システムのシステム障害が発生しました。
シスコ製スイッチの「世界初のバグ」ということで話題にもなりました。
障害の原因について調べていくと、分かりづらい点と疑問点がいくつかありました。
今回は各記事から読み取れなかった部分を技術的に解説してきます。
障害の原因「4台のDBサーバーが停止」
まずは障害の原因について見ていきましょう。
下の図を見てください。
これは、ITproの編集部の方が作成した
「全日本空輸の国内線旅客システムの構成図」※1です。
システム障害が起きた理由を簡潔に述べると
このDBサーバー4台が全て停止したことが原因です。
全日本空輸の国内線旅客システムの構成図※1
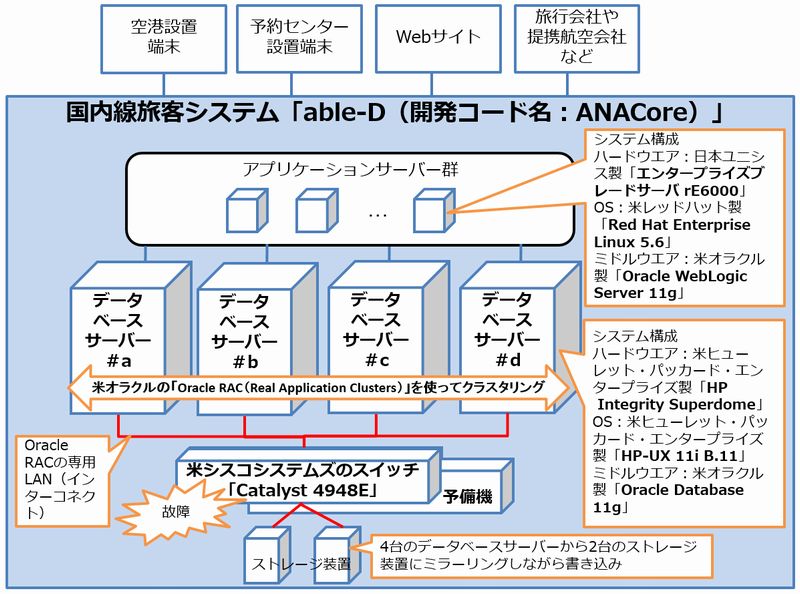
どうして同じサーバーが4台もあるのか?
DBサーバーが4台もある主な理由は、
「一部のサーバーが壊れてもシステムが停止しないようにすること」と
「性能を上げる」ため。
2台以上のサーバーで同じ処理をさせためには、
色々と注意しないといけないことがありますが、
その一つが「データの整合性」です。
「データの整合性」とは複数のサーバーで同時に処理をしているため、
データが矛盾しないように一貫性を保つことです。
ANAのシステムでは「ORACLEのRAC」というソフトを使って
「データの整合性」を担保しています。
RACとは?
ではそのORACLEのRACについて確認しましょう。
ORACLEのRACは
複数のサーバーがあたかも一つのORACLEデータベースとして利用する仕組みです。
これを「クラスタリング」と言います。
今回のシステムでは、
4台のサーバーと2つのストレージ(データが保存されている機器)があります。
2つのストレージには同じデータを書き込んでいます。
そのため、1台のストレージが壊れたとしてもデータが消えることはありません。
4台のサーバーからはそれぞれ2種類のケーブルが出ています。
サーバー同士をつなぐための「インターコネクト用ケーブル」と、
「ストレージにデータを書き込む用のケーブル」です。
「ストレージにデータを書き込む用のケーブル」はイメージがつきやすいと思いますが、
「インターコネクト用ケーブル」はなかなか聞かないですよね。
「インターコネクト用ケーブル」とは、サーバー同士がお互いに稼動しているかどうかを確認したり、データを転送するのに使われます。
スイッチはどうやって壊れていた?
今回、通信障害が起こったのは、
「インターコネクト用ケーブル」が接続しているスイッチでした。
先に引用したITProさんの記事の構成図では、
「インターコネクト用」と「データを書き込む用」のスイッチが同じスイッチに見えますので、
壊れ方としては、以下のどちらかだったと推測しています。
①データを書き込む用の通信(パケット)は通れたけど、インターコネクト用の通信は通れなかった
②インターコネクト用で使用しているケーブルが接続されているポートのみ壊れていた
つまりスイッチは一部が正常に稼動していて、
一部が壊れていた「半死」状態となっていました。
インターコネクトで使っていたスイッチの故障が、
最終的にはサーバー全台の停止につながりました。
システム障害の原因はスイッチのバグ?
原因はスイッチのバグであると結論付けられています。
今回のシステムでは、
「スイッチが故障したときに自ら通知する機能」(これをSNMP Trapと言います)を使っていました。
スイッチも一台だけで運用しているのではなく、
壊れたとき用に、もう一台予備があります。
正常な動作であれば、SNMP Trapを検知したときに、スイッチが切り替わりますが、
今回はそのSNMP Trapが送信されませんでした。
つまり、監視機能で正しく検知できなかったことによって、
今回の障害は発生しました。
詳細な解析結果についてはまだ分かっていません。(シスコさんの発表を待ちます)
どのように壊れていたのか……
ハードウェアの問題なのか、ソフトウェアの問題なのか?今後も発生しうる問題なのか?
色々と疑問は募るばかり……
回避する対策はあったのか?
「半死」という状態では救いようの無いと思われるかもしれません。
むしろ、24時間ほどで全復旧され、
さらにその翌日には改善策をとったことに賞賛の声が寄せられているそうです。
(私もそう思います)
ANAが取った対策は、
「スイッチが故障シグナルを出さない場合でもDBサーバーからスイッチ故障を検知できるように改善」でした。
これも詳しく書いていないので推測になりますが、
恐らく以下の「L7ヘルスチェック」のような対策だったと思います。
L7ヘルスチェック
ヘルスチェックとは
対象機器が稼動しているかどうかを確認する監視機能のことです。
L7とは「OSI参照モデルのレイヤー7」のことです。
ここでは詳細を省きますが、
L7ヘルスチェックを使うことによって、アプリケーションレイヤーでのチェックが行えます。
そのため、今回のような「対象機器が稼動しているように見えますが、
使いたいサービスがうまく使えない」という場合に有効です。
終わりの一句
いかがでしたでしょうか。
システムを障害から守るためには、そして原因を追求するためには、
一筋縄でいかないことが分かりましたでしょうか?
このブログを書いた感想を一句でまとめたいと思います。
障害の
復旧の影に
勇者あり
◆参考サイト◆
※1 IT Pro
ページより画像引用
(※記事全文を読むには会員登録が必要です)
-
SNS
-
投稿日
-
カテゴリー
BTM Useful